Over-Parameterization and Optimization II - From Linear to Quadratic
If the canonical representation of the network has a nicer optimization landscape than the deep parameterization, could we use it to get better optimization algorithms for a non-linear neural network?
Last time, we looked at the connections between the regular parametrization of deep linear networks and their canonical parameterization as linear functions over . We saw that the deep parameterization introduced unnecessary critial points to the loss landscape, making it harder to guarantee convergence for gradient based optimization algorithms. There’s been some work explaining why this change to the loss landscape doesn’t hurt optimization, and maybe even why it can benefit generalization and optimization.
In this post however, we will try to see if we can optimize directly in the canonical space, which is linear and well-behaved. To make things interesting, we’ll look at a non-linear model for which we can do this kind of optimization - a “quadratic neural network”.
The Quadratic Neural Network
If you had to name the simplest possible non-linearity before ReLU because such a big deal, you would probably say that the squared activation was the simplest. It only requires multiplication of the input with itself, which is both very efficient computationally and means that the neural network is a realization of a polynomial function, which is something we know a lot about1.
So, a step from linear networks towards deep ReLU networks could be a network with the squared activation. We will start by looking at a shallow network of that kind - our input will be , which will be multiplied by a weight matrix . Then, every element will be squared, so our activation function is . Finally, this hidden layer will be multiplied by a vector to produce our prediction. Denoting the ‘th row of as , we can write our function as following:
A diagram of the network will look like this:
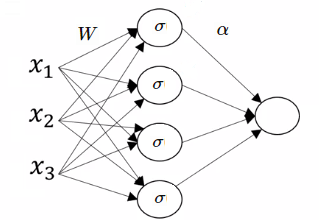
We immediately see that every set of parameters encodes a degree-2 polynomial over . As we’ll now see, this representation is over-parametrized in a very similar way to the linear example of our previous post.
Invariances in the Deep Representation
For deep linear networks, we saw that many different parameterizations actually encoded the same function. For example, we saw that multiplying and dividing two layers by the same scalar didn’t effect the function. We also saw that permuting the inputs and outputs of neurons in a corresponding way also did not change the function. These invariances return in our quadratic network, with slight changes.
First of all, the permutation invariance is the same - if we permute the rows of and the entries of in the same order, it would simply be a different order of summation over the neurons. Since the order of summation doesn’t change the function, our parameterization is invariant to this kind of permutation.
Next, looking at a single neuron , if we multiply by a scalar while dividing by - the neuron’s output doesn’t change:
This means that we have an invariance to scalar multiplication of inputs and outputs of the same layer, when one scalar is the inverse square of the other.
These invariances suggest, like we saw last time, that there is some canonical parameterization for which every set of parameters encodes a unique function, and all functions from our family can be encoded. Luckily for us, it is easy to describe such a canonical space for the quadratic network.
The Canonical Representation - Symmetric Matrices
The quadratic neural network is a fancy name (and parameterization) of degree-2 polynomials. This means that we can use degree-2 polynomials over as our canonical representation. This means our canonical parameterization has free parameters - a coefficient for every pair of elements in .
However, for convenience of notation and for a clearer geometric understanding, we will use an equivalent view of degree-2 polynomials - the view of such a polynomial as a quadratic form. Instead of viewing the polynomial as a linear function over the space of the products of pairs of elements in , we can look at a polynomial as a symmetric matrix in 2. The polynomial function in this space can be described as both a quadratic form and a matrix inner product:
Now we just need to map the network parameterization to this matrix parameterization, which can be done in the following way:
So, our mapping from the parameterization of to the parameterization of is:
Taking this matrix view instead of the regular degree-2 polynomial view gives us an additional geometric understanding of , the number of hidden neurons in our network - it is the rank of the matrix! This leads us to the understanding that all degree-2 polynomials over can be described using a quadratic neural network with hidden neurons.
Now that we have this geometrical understanding of our canonical space, we can move to seeing how this understanding can help us with optimizing our neural network - both in the full rank domain and the low rank domain.
Optimizing the Quadratic Network
Having described our model in two parameterizations, we can now choose in which one we will do our optimization. We can either optimize in the deep parameterization using SGD (as is usual for neural networks), or use SGD in polynomial/matrix space.
SGD in the Deep Representation
We can derive the gradients of the parameters either through backpropagation, or by explicitly calculating them from the matrix parameterization (by calculating and ). The gradients turn out to be:
Like we saw for the linear example in the previous post, this parameterization creates “ghost” critial points which don’t exist in the canonical representation. These critical points are introduced by the parameterization, since the function isn’t linear in it’s parameters. For example, having and makes the gradient of the function equal zero regardless of the loss (exactly like in the deep linear networks).
Another problem that comes up again, is the one introduced by the scalar multiplication invariance - an imbalance between and can cause the gradients of the function to explode or vanish, and the gradients in general are highly dependent on the parameters.
This means that if we don’t initialize correctly when optimizing in this representation, we can run into problems.
The Canonical Gradient
Like we did for deep linear networks, we can look at the gradient of the canonical parameterization - that parameterization is linear3, so we should expect it to be independent of . Indeed, the gradient of is simply:
This is great - we have a non-linear neural network that we can reason about using the same tools we used for the deep linear networks. We can now do the same thing we did for the linear case, and explore the effect of the deep parametrization on the gradients. Neglecting higher order terms of , we can look at the deep model in the canonical representation, after a deep gradient step:
And so, while the canonical gradient is simply , the deep gradient in it’s canonical form is:
This expression is a bit less elegant than the linear network example, but it has the same kind of behavior as the linear case. We see that the gradient’s norm is dependent on the parameterization (and it’s balance between layers), as well as that the gradient’s direction is also dependent on the parameterization. We can see this by looking at the scalar invariance of the parametrization, where we can multiply by and divide by (restricting ourselves to for simplicity):
We see that as we play around with , the gradient can be in any direction of the convex combination of and .
It is also easy to convince ourselves that the deep gradient, for an infinitesimal , is always positively correlated with the canonical gradient4 (like the linear case, where the gradient was transformed using a PSD matrix). Seeing this behavior both in the linear and the quadratic case, we can understand how this should be the case for general linear canonical representations - the gradient will always be positively correlated with the canonical one, with it’s norm also being strongly dependent on the parameterization.
Theoretical Insights From the Canonical Representation
I should explain at this point that the quadratic model we’re talking about has been studied theoretically quite a bit. It has interested researchers because it is a non-linear neural network that is easier to probe theoretically than ReLU or sigmoid models. There are two papers that are most relevant to us when talking about SGD in the deep representation.
The first paper studies the loss landscape of the quadratic model by explicitly calculating it’s Jacobian and Hessian (not a fun experience). They show that if we have hidden neurons and a fixed vector, then all minima are global and all saddle points are strict. This means we should expect SGD to converge.
The second paper improves on the result and shows that under fixed and with weight decay assumptions, it is enough to have hidden neurons for all minima to be global and all saddle points to be strict.
These results were hard work since they had to fight the artificially complex loss landscape caused by the over-parameterization. However if we look at the canonical representation of the model, this result is trivial and does not require any artificial assumptions like fixed weights or specific initialization. If we have hidden neurons, all of the symmetric matrices in are expressible by our model and so we have a convex optimization problem over a convex set, and SGD obviously converges with no further restrictions. This is a great win for the canonical representation view of the model, since it is much more elegant and clear description of the problem, allowing for minimal assumptions and a deeper understanding.
This view also highlights more clearly why the result is only valid for hidden neurons - the moment , the symmetric matrices that can be expressed by our model are only those which are of rank or less. When , this does not span all of the symmetric matrices and the problem in it’s canonical representation becomes a convex loss function over a non-convex feasible set. This means that our convex optimization knowledge is no longer enough, and we will need new ideas for reasoning about the low-rank domain.
While we think about new theoretical ideas for these kinds of optimization problems, we can still try to use the canonical representation to develop new optimization algorithms for our model, and that’s what we’ll do next.
(Projected) SGD in the canonical representation
Optimizing in the canonical space when is straightforward, since we simply do SGD until we converge (and we’re guaranteed to converge). However, when , we are optimizing over a feasible set embedded in the linear space of symmetric matrices. We can still take gradient steps, but we will have to project our solution onto the feasiblt set (either at the end or after every gradient step).
So, we will need to know how to find the rank- matrix closest to a given symmetric matrix . Every symmetric rank- matrix can be decomposed into the weighted sum of symmetric rank- matrices, which leads us to the following optimization problem for the projection:
The solution to this optimization objective is to take the eigendecomposition of and setting to be the largest eigenvalues (in absolute value) and to be the corresponding normalized eigenvectors. This also immediately gives us a way of obtaining the closest quadratic network with hidden neurons to a given symmetric matrix .
We can now describe an optimization algorithm for the quadratic network that uses the canonical gradient step as opposed to the deep gradient. Given the model in it’s deep representation, we calculate it’s canonical representation as and take a gradient step of the form . We then perform an eigendecomposition of the matrix and set and to be to top- spectrum of the matrix.
We can’t guarantee convergence for our projected algorithm when (the loss surface might have non-artificial local minima), but we can guarantee that we’ve solved the exploding/vanishing gradient problem. This algorithm is slower than regular SGD due to the eigendecomposition step, but if we use large mini-batches this difference disappears (at least theoretically, in a workd with no GPUs).
If you want to delve deeper into this optimization direction, you can take a look at this paper which develops a similar algorithm for the quadratic model, with a different projection step that tries to make the algorithm faster. They also give convergence guarantees under the assumption of Gaussian input and the squared loss.
Toy Examples in the Low-Rank Domain
The problem of optimizing a convex loss over a non-convex feasible set can be something hard to visualize. In these kinds of situations, it’s often advantageous to look at a toy example which should make thinks clearer and more visual. It’s also about time we saw a picture in this blog series…
If we want to visualize the low rank, non convex manifold embedded in canonical space, we will need to look at a low dimensional setting that allows it. Luckily, we can visualize the smallest low rank matrix manifold in . We will look at quadratic networks where that have one hidden neuron. This means our canonical representation is symmetric matrices in , which can be parameterized using three parameters and visualized in (this basically takes us back to the degree-2 polynomials coefficients parameterization). The rank- matrices of this form can be described as matrices of the form , with and . This means that there are two real-valued parameters for our feasible set, which makes it a union of two-dimensional manifolds embedded in .
So, how does this union of manifolds embedded in the canonical space look like?
This plot shows the manifolds, where the axes correspond to the coefficients of the degree-2 polynomial (the rank- constraint gives us the equation ):
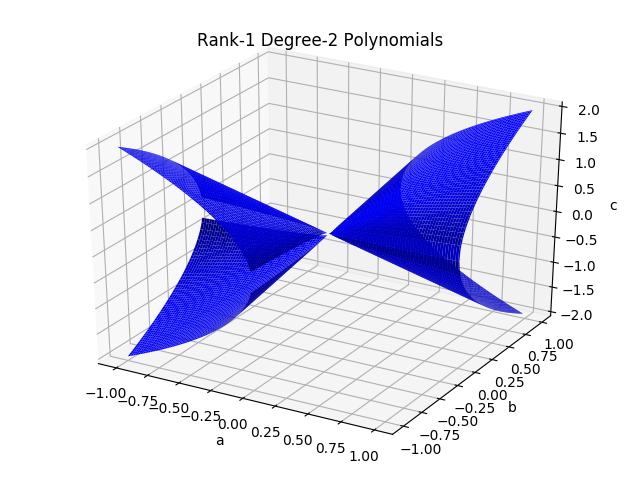
This is cool - we see that while the manifold is definitely non-convex as expected, it still has quite a bit of structure. The manifold consists of two cones that meet at the origin and go out in opposite directions. Optimizing in the deep parameterization makes every gradient step be restricted to this manifold, while optimizing in the canonical space means we take steps in the linear space in which the manifold is embedded, and then project back to the closest point on the manifold.
It is interesting to see in this visual example how the two algorithms perform and behave. They both make trajectories on this manifold, attempting to reach the global optimum, but their dynamics are quite different. Let’s look at the following experiment - we define a loss landscape over the symmetric matrices as being the squared loss between the model’s predictions and the optimal matrix’s prediction, where the input is Gaussian and the optimal matrix is rank-, :
We then minimize this loss, which is convex in the canonical spcae, using both optimization algorithms. We plot the trajectory of both algorithms throughout the optimization process, leads to the following trajectories:
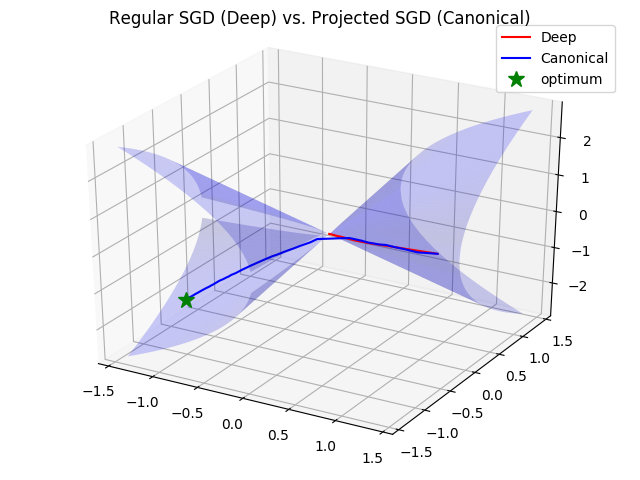
This is interesting - since the initial matrix and optimum matrix sit on separate manifolds, the optimization process had to go through the origin in order to reach the optimum. For the projected SGD algorithm this wasn’t a problem and the algorithm went through the origin (which isn’t a critical point) and reached the optimal matrix. However, the regular SGD has a critical point at the origin, and the closer we are to the origin the smaller the norm of the weights are, which cause the gradients to be small. The regular SGD experienced a vanishing gradient problem when it got close to the origin, causing the optimization to get stuck at the origin and not reach the second manifold…
You may say that this problem is highly hand-crafted, and that it only happens when we restrict the matrix to be of rank-. If it were full rank and able to span the entire canonical space, there should be no problem in optimizing the model with regular SGD because it wouldn’t be drawn into the origin and get stuck. The thing is, for SGD in the regular parameterization, every neuron’s output is restricted to the rank- manifold - the model is able to span the entire space only because it is a summation of these neuron outputs. For example, if we had two neurons on the same side of the manifold and the optimum was in the other halfspace, every neuron would have to separately cross the origin and they could both get stuck. We can see this example in the following plot, where the red line is the complete model trained with SGD, and the black lines are it’s two neurons (the optimum is a rank- matrix this time):
The last thing to note, which shows even more how the specific parameterization effect SGD, is that this pitfall of the dynamics can be avoided by careful scaling of , and the learning rate!
If we keep the same initialization but scale up and down such that the model doesn’t change, the dynamics won’t get stuck at the origin because the gradients of won’t vanish - . However, if we adversarially choose the optimum to be such that has to change considerably, the optimization with SGD will still take a long time… You can see this in the next plot:
All of these experiments make us see that SGD in the deep representation can work, but it doesn’t work out of the box and requires careful understanding of the effects of the parameterization on the dynamics of optimization. This can make us want to go all in on the projection algorithm, but these sorts of pathological issue of SGD won’t necessarily replicate in higher dimensions. We can check this using a binary MNIST problem.
MNIST Experiments
To see if the projected SGD algorithm for the quadratic model is better than regular SGD for more realistic problems, we can try to solve the binary MNIST task (classifying 3s and 5s). In the following plot you can see learning curves of the two optimization algorithms, along with the corresponding Frobenius norm of each model in the canonical space. The rank for the model was chosen to be , and the only difference aside from the optimization algorithms was the initialization, where the projected model was initialized with zeros since it is possible to do so (however, these results replicate for other initializations):
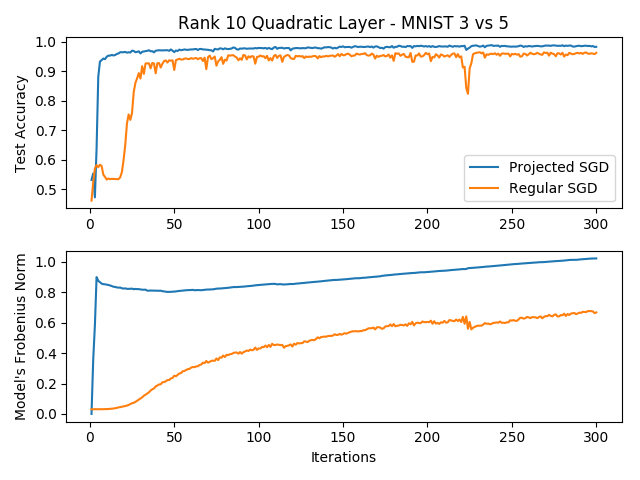
We can see several interesting things, the first of which is that the projection algorithm seems to perform much better than regular SGD in this low-rank regime. Not only is the accuracy much better, but the variance in the learning curve is smaller and more consistent. This result is reproduced under different initializations and learning rates, but I admit that I didn’t try playing around with the initialization like in the toy examples (I just used a standard Glorot initialization), and that could have improved the performance of SGD. We see that the complete breakdown of SGD we saw with the toy example does not happen with this high dimensional problem, but it is possible that the search space was restricted by the initializations of that predetermined the manifold that every neuron will sit on, leading to a sub-optimal solution.
Another interesting thing to note is the model’s norm in the canonical space. The projected SGD has an initial large boost to the norm, caused by the large gradient of the loss function. It then changes very slowly, searching for the optimum. The regular SGD algorithm however, has a slowly increasing norm that is caused by the gradient being dampened by the initially small norm of the model. Once the model grows larger, the gradients grow as well, causing the optimization to be less stable.
However, we shouldn’t get too excited - if we use Adam as our optimizer for the deep representation, the optimization becomes more stable and the results are very similar to the projection algorithm. This is reasonable, since Adam can adjust the learning rate to be smaller when the model has a larger norm. Also, when the rank we use is larger (), the advantage of the projected SGD algorithm over SGD dissappears completely. This can possibly be attributed to the fact that when is large, we have enough initial neurons in every manifold to express the optimal matrix…
You can get the code of this experiment here.
Still, this can make us hopeful about using this projected SGD algorithm in practice with these quadratic functions, and maybe even incorporate these models into a deep neural network. In order to do that and make our model and optimization algorithm practical, we need to generalize them such that they work with multiple outputs. This turns out not to be so straightforward, and we’ll tackle it in the next post.
Footnotes
-
It also has some advantages when we are dealing with private ML, since homomorphic encryptions work well with polynomials and multiplications, and not so well with functions such as the max function… ↩
-
Mapping the coefficients of ^{2} to the diagonal entries and mapping to and , we can see that the polynomial function is equivalent to . ↩
-
It isn’t a linear function of , of course, but it is a linear function of the mapping . When is mapped to the canonical Hilbert space, our function becomes a linear function. ↩
-
Taking the inner product with , we get: ↩