Over-Parameterization and Optimization I - A Gentle Start
Deep, over-parameterized networks have a crazy loss landscape and it’s hard to say why SGD works so well on them. Looking at a canonical parameter space may help.
Recently, there have been some interesting research directions for studying neural networks by looking at the connection between their parameterization and the function they represent. Understanding the connection between these two representations of neural networks can help us understand why SGD works well in optimizing these networks, and hopefully why SGD and over-parameterization seem to lead to strong generalization…
In this blog series I’ll review some of these concepts using toy examples, and develop some interesting ideas for how we can use this view to both develop new optimization algorithms, and explain the success of regular optimization methods for neural networks.
- Over-Parameterization
- A More General View
- Exploring Parameterizations and Gradient Fields
- Further Reading
- Footnotes
Over-Parameterization
Neural networks are over-parameterized, meaning the same function can be represented by different sets of parameters of the same architecture. We can look at a simple example to demonstrate this - a two-layer linear neural network parameterized by the vector and the matrix , where out input is in :
Clearly, this is just a linear function, which means we only need dimensions in order to define it, but we have more than . We have many ways of representing the same linear function with different parameters - if we permute the rows of and the entries of in the same way, the function will stay the same. If we multiply by a scalar and divide by that same scalar, the function will stay the same. These invariances of the model are relevant not only for linear networks, but for piece-wise linear as well (like ReLU networks).
You may ask - so what? As long as we are able to express a rich and relevant family of functions with our parameterized model, why should this over-parameterization matter to us?
We will now see that this over-parameterization leads to a very different optimization landscape for SGD.
Parameteric and Canonical Spaces
If we want to compare the two-layer linear network with the family of linear functions, we will need to define the two parameterizations and the way they are connected to each other. We already know what the parameteric space is - this is the over-parameterized model defined by and . The canonical representation in our case will be the space of linear functions in , parameterized by .
We call the canonical space “canonical”, because every set of parameters in it define a unique function, and every set of parameters in the parameteric space has a corresponding function in the canonical space. We are dealing with linear functions for now, so mapping from the parameteric space to the canonical is simply a matrix multiplication:
Note that we can’t map back from the canonical space to the parameteric, because the mapping isn’t bijective - a single has many possible parameterizations in the parameteric space… Also, note that while we are dealing with linear functions, the mapping between the two spaces is not linear in .
Gradient Dynamics Between Spaces
Now that we’ve established these two spaces, both essentially representing the same functions, we can compare their gradient dynamics. Given an example and our convex loss function , we can write down the gradient of the loss with respect to the general parameters using the chain rule:
We see that the parameters are only present in the derivative of the function , so we can ignore the gradient of the loss and focus on the gradient of under the two different parameterizations. For the canonical space, the gradient is just the gradient of a linear function:
For the parametric representation, we can use the chain rule to get the gradient (or calculate it directly):
Now we start to see something interesting in the dynamics of the deep representation - while in the canonical space all functions have the same gradient with respect to (since the space is linear), in the deep representation the gradient depends on the parameterization. For example, given a fixed parameterization, if we increase the norm of all of the weights - the gradient will have a larger norm as well. This means that as training progresses and the norm of our weights increase (as they generally do), the gradients tend to grow as well (ignoring the gradient of the loss which usually becomes smaller).
We can see even more interesting phenomena when we look at the models after a small gradient step. Assuming we use an infinitesimal learning rate , the model after a canonical gradient step will be:
However, the model after a parameteric gradient step will be (ignoring second order terms of ):
And look at this - we already know that the deep parameterization affects the norm of the gradient, but now we see that the deep parameterization also affects the direction of the gradient. The direction of the canonical gradient is along the axis defined by the input , but the parameteric gradient is along the axis of the vector .
A Variety of Parametric Gradients
Looking at the example above, it is interesting to explore how varied the direction and norm of the gradient can be, depending on the parameterization of the same function. There is a general transformation to the parameters of the deep model that we can look at that make the function remain the same - if we multiply by some invertible matrix , and multiply by it’s inverse, we are left with the same function we started with:
Now, this means that while a given function has a canonical gradient with a unique direction and norm, that same function in a two-layer parameterization can have many possible gradient directions and norms - each defined by an invertible :
Basically, by choosing the right we can get a gradient to point anywhere we want in the positive halfspace of (since the matrix multiplying is PSD)!1 If we can choose any two directions in a certain halfspace to be our gradient, it turns out that two different parameterizations of the same function could have negatively correlated gradients.
This is very interesting. The canonical space of functions we are working with is linear and we know a lot about how optimization works in it (namely, we can easily prove convergence for convex losses). However, once we over-parameterize a little we get completely different optimization dynamics which are much harder to deal with theoretically. These over-parameterized gradient dynamics depend on the parameterization at every time step, which means that if we want to guarantee convergence we have to pay attention to the entire trajectory of the optimization…
Take-Aways From the Linear Example
This 2-layer linear example is far from a deep convolutional ReLU network, but we can already see interesting phenomena in this example that exist in optimization of real networks.
The main thing we can gather from this example is the importance of balance netween the norms of the layers at initialization and during the optimization process. Looking at the parameteric gradient, , if either the norm of or the norm of is very large, then the gradient of the function will be huge even if the other’s norm is small. This means we need to initialize the parameters such that they have similar norms, like we do in practice. This issue arrises in real neural networks as the exploding/vanishing gradient problem…
Another interesting thing we can gather, is the possible importance of learning rate decay for deep models. For example, if the minimum of our loss function was some linear function with a very large norm, than a large learning rate could cause the dynamics to blow up when the parameters become large (since the gradient norm grows with the parameters). However, a small learning rate would take a very long time to converge. This suggests a new motivation for learning rate schedules that stems from the effects of the norm of our model on the gradient norm.
A More General View
In the next post I’ll be exploring non-linear neural networks, but before we get there we should take a step back and try to generalize what we just saw for deep linear networks.
We had two ways of looking at the same family of functions. The first was a canonical parameterization, where every function in our family had a unique parameterization and the function space was linear. The second was an over-parameterized representation, where every function in our family had many possible parameterizations. We also had a non-linear mapping from the parameteric space to the canonical one. Let’s define the canonical parameters as and the deep parmeterization’s parameters as . The mapping between a deep parameterization and it’s corresponding can be written as .
So far we looked at how the gradients behave in the two spaces for the linear 2-layer example, but it should be interesting to see more generally how the loss landscape looks like between the two spaces.
The Loss Landscape
The first thing we care about in a loss landscape, is where are the critical points and are they well behaved?
For the canonical representation, if we assume that the functions in this representation are linear (like in our example and in future examples), then if the loss is convex we are very happy - there is a unique minimum to our function and we are guaranteed to reach it using SGD!2
As for the parametric representation, things aren’t necessarily as simple. As a quick example, we can look back at out linear example where and . Looking at the gradients, this is a critial point of the loss landscape no matter what loss we have, and it generally isn’t a minimum (it’s a saddle point when the optimal function isn’t the zero function). So, if the canonical space has a unique critical point (the global minimum) but the parameteric space has more than one critial point - where did the additional critical points come from?
Well, we know how the two parameterizations are connected - they are connected by . So, we can look like before at the gradients in the two spaces and ask when they are zero. Using the chain rule and the fact that :
For a given parameterization , we see that the canonical and parameteric gradients are connected by a linear transformation define by the matrix . This immediately implies that if maps to the unique global minimum of the canonical space, then it is also a critical point (a global minimum) of the parameteric space, since and the relation between the gradients is linear. This is a nice sanity check…
However, the additional critical points come up in the situations where and . Since the connection between the gradients is through a matrix multiplication, this can happen only for s for which the linear transformation between the two gradients is not full rank. In such a case, has a non-empty kernel and non-zero canonical gradients can be mapped to zero parameteric gradients, which means that we get a critical point where there is no such critical point in the canonical space.
The Formation of “Ghost” Saddle Points
So, For which is of partial rank?
To understand this, we need to more explicitly define . Every column of this matrix defines how a single entry of changes every entry of . If a set of these columns is linearly dependent, or equal to zero, the matrix can be of partial rank.
This happens for example when two row vectors of the same weight matrix in a neural network are identical/parallel (meaning two neurons are identical) - in such a case the two sets of columns will be linearly dependent. Another example can be “dead neurons” in ReLU networks - these neurons are always zero and so the outgoing weights from them don’t effect the actual model (and so their column is a zero vector).
In practice, when the neural network is large enough and the initialization is good, we don’t see this happening and the network is able to converge to a global minimum (with a loss of zero). Hui Jiang built on the above kind of reasoning in his paper to explain why highly expressive neural networks don’t get stuck in local minima even though there are so many in the loss landscape.
The Exploding and Vanishing Gradients Problem
Just like we explored the loss landscape using , we can do the same sort of analysis to explain more generally why there are exploding and vanishing gradients.
Since depends on , it is reasonable to believe (and it is the case in practice) that there are many s for which the operator norm of is very large or very small. In such cases even though the canonical gradient is of a reasonable norm (assuming has bounded norm), could still increase/decrease the norm of the gradient considerably, causing the gradient to vanish or explode.
Why the Canonical Gradient is so Canonical
Finally, it is interesting to explore the interesting property we saw for the linear case, where for infinitesimal learning rates we always had a positive correlation between the parameteric gradient and the canonical one - is this a general property of over-parameterized models vs their linear canonical representation?
The answer is yes - if we have a linear canonical representation for our model and a differentiable function mapping a parameterization to that canonical representation, all gradients of the parameterizations of the same function will be positively correlated with the canonical gradient (while not necessarily positively correlated with each other).
Let’s prove it - we will denote our canonical parameterization as and the parameteric representation as . We will denote the differentiable mapping from to as . Finally, we will denote the mapping of our input to the canonical linear space as .
We know that the function in the canonical space is linear, so we can easily write the function before and after an infinitesimal gradient step:
This means that the gradient of the canonical function in the canonical space is . We will now do the same process for the parametric gradient - we will calculate the change in and then map the new to the canonical space. The gradient of can be calculated in the canonical space using our mapping and the chain rule:
This means the new can be written in the following way:
We can now map that new parameterization to the canonical space and get our new canonical representation, after the gradient:
Since is infinitesimal, we can look at a first order approximation of around and neglect any higher order terms:
We see the new function after a parametric gradient is indeed different from the one after a canonical gradient - in both cases we have a function that changes by adding a vector to the original function. In the canonical gradient step, that vector was , while in the parameteric step, that vector was .
Since in both cases is the Jacobian around the same (the initial ), is PSD and so the two gradients are positively correlated.
Exploring Parameterizations and Gradient Fields
Before we move on to non-linear networks, it’s interesting to visualize just how much the parameterization we use can effect the gradient-based optimization of our model. Earlier, we saw that playing around with the parameterization of a deep linear network without changing the underlying function can drastically change the gradient of the function. Now, we will visualize this along with other possible parameterizations of linear functions!
We will visualize the dynamics by plotting the over-parameterized gradient on top of the canonical gradient. We will look at functions in and for any original gradient value we will plot the one induced by the over-parameterization. We can look at the following example for regular canonical dynamics before we move on to more interesting dynamics:
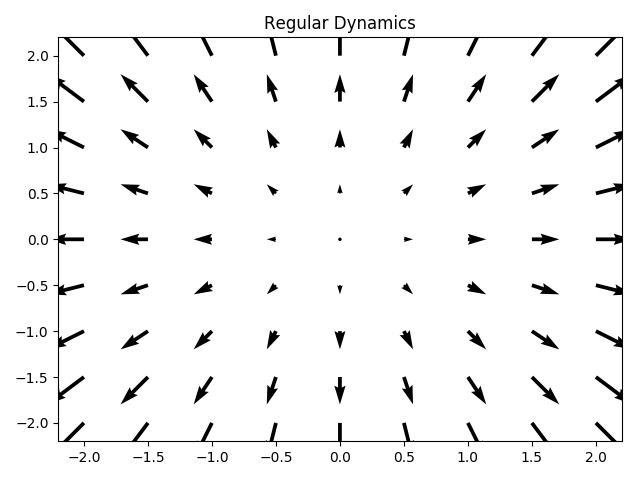
Every arrow’s starting point in the above plot is where the original gradient ended. The arrows are scaled down a bit to make things clear, so their direction and relative size are what we should look out for…
We see that in the regular dynamics, the canonical gradients remains the same - every arrow continues to point in the direction that it started in, and every arrow around a circle of the same radius has the same size. Let’s see how this changes with different parameterizations.
Squared Parameterization
Following a recent paper that studies the generalization effects of over-parameterization, we will look at a very simple linear function in . The canonical representation of such a function is simply - two positive numbers that are the coefficients of the inputs:
However, we can use a different parameterization for our function, parameterized by :
This sort of parameterization is reminiscent of adding a layer to the linear neural network - the function remains the same but the gradient changes. As we saw, we can calculate how the gradient to should change when we are using this parameterization (and optimizing over ) by computing the PSD matrix which multiplies the canonical gradient.
This matrix is diagonal since only depends on , and we get the following diagonal entries:
This means that when w_{i} is large, we should expect the gradient to grow larger. On the other hand, if w_{i} is small we should expect the gradient to become smaller. This means that under this squared parameterization, the optimization is biased towards the features which are already deemed as important by the model. We can now look at the gradient field for different values of :
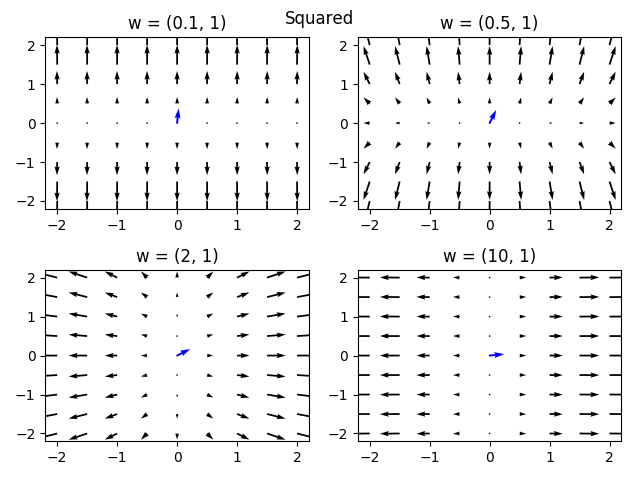
The blue arrow depicts the vector over the same axes. Indeed, we see that the gradients in this parmeterization are transformed so as to emphasize the gradients to parameters which are already large. In the extreme cases (top-left and bottom-right plots), we see that the function changes almost completely in the direction of the large weights, with little to no change to the small weights. This sort of parameterization induces sparsity - if we initialize the values of to be very small, then the weights more dominant in the optimization will get a head start and leave the other weights behind.
Inverse Parameterization
Just like we did for the squared parameterzation, we can use the following parameterization instead:
We can now calculate the PSD matrix in the same way and get:
We get the opposite of the squared parameterization - large values of are punished and their gradient is made smaller. We can see this in the gradient flow as well:
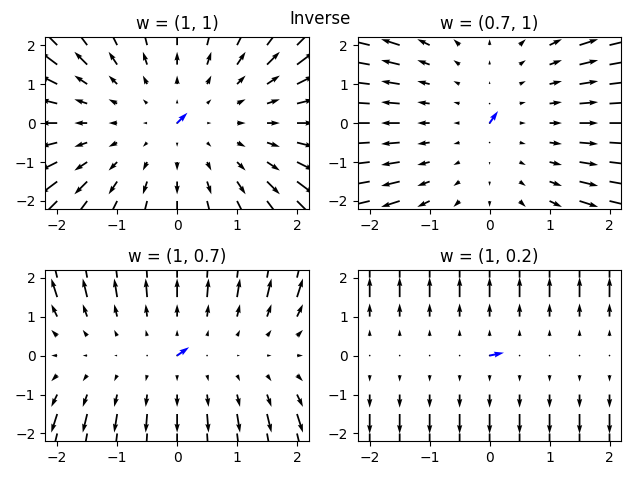
This parameterization has a strong bias towards weights that are relatively small in our model. It is reasonable to conjecture that this sort of parameterization is biased towards solutions with many small values for the weights, possibly minimizing the norm of the solution.
Polar Parameterization
We would be remiss not to look at the classic parameterization - polar coordinates!
Like before, we can calculate the Jacobian matrix and visualize the gradient field for different parameterizations (changing this time):
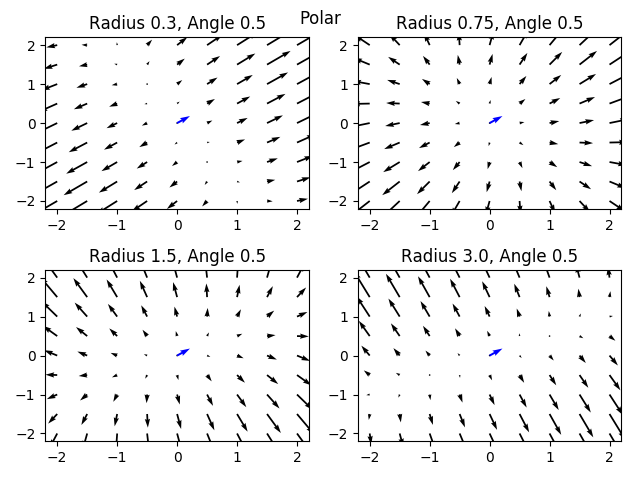
We see that this parameterization acts differently than the previous parameterizations - when , we get the canonical gradient field. However, if is small we get a bias of the optimization towards the direction that the model is currently pointing to. If is large however, the optimization biases us towards the orthogonal direction to the current model.
I wouldn’t try to optimize my linear model under this parameterization, but it is pretty cool…
Deep Linear Parameterization
Finally, we can take a look at our original parameterization of a deep linear model, for the same function with different parameterizations determined by the invertible matrix. We will assume that and look at how different matrices change the optimization landscape:
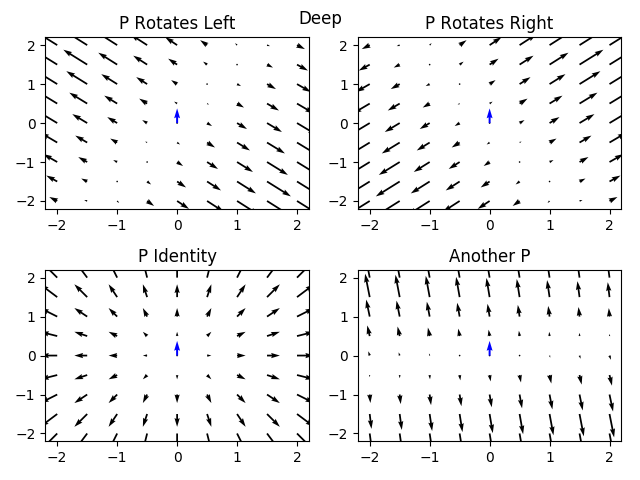
We see that we actually can completely change the optimization landscape by choosing different matrices, while the underlying function (the blue arrow) remains the same!
Further Reading
This sort of comparison between deep and canonical representations is used to both understand why neural networks are able to reach global minima of the loss landscape, and recently to start showing why they generalize well. In the next posts we’ll try exploring how we can develop optimization algorithms using this view.
Deep Linear Networks
A few papers from Sanjeev Arora and Nadav Cohen, along with other collaborators, address the dynamics of optimizing deep linear networks (deeper than our linear example).
The first paper studies depth and it’s effect on optimization. It shows that under certain assumptions on the weight initialization, depth acts as a preconditioning matrix at every gradient step (similar to the PSD matrix we saw in our small example). They also show that this kind of preconditioning cannot be attained by regularizing some type of norm of the canonical model - over-parameterization seems to be a different kind of animal than norm-based regularization.
In the second paper, the authors extend their results and show a convergence proof for deep linear networks under reasonable conditions on the random initialization.
In their recent, third paper, they move to studying generalization by showing that depth biases the optimization towards low rank solutions for a matrix completion/sensing task. There have been previous results showing that SGD creates this sort of bias and it is a strong belief today that SGD is a main factor in the generalization of neural networks. This work shows that not only does SGD bias us towards simple solutions, but that over-parameterization may also be a factor. As in the first paper, their results suggest that depth is a different animal than regularizing a norm (nuclear or otherwise), being more biased towards low rank than norm regularizations.
A nice paper by Ohad Shamir explores the optimization landscape of deep linear scalar networks, showing cases in which depth hurts optimization. In particular, Shamir shows that for certain conditions we need the number of gradient steps to convergence to be exponential in the depth of the network.
Finally, a recent paper by Nathan Srebro’s group analyzes an even simpler over-parameterization of the linear function - the squared parameterization discussed in the previous section. In their paper, the authors analyze the optimization at different initialization scales and show that in the limit of large initial weights, the model converges to the minimal solution, while in the limit of small initial weights, the model converges to the minimal solution, continuing the line of results showing that over-parameterization leads to clearly different implicit regularization. They also derive an analytic norm that is minimized for every scale of initialization, showing that the initialization-dependent solution moves from the minimal to the minimal continuously as we decrease the scale of initialization of the network.
Non-Linear Networks
This sort of analysis is very nice for linear networks where we can clearly define the canonical representation, which happens to be linear and behaves nicely. However, when we move to deep ReLU networks for example, we don’t even know how to properly describe the canonical representation, and it is incredibly high dimensional. Still, there are a couple of works that try to use the connection between the two spaces to explain why SGD works in the deep representation.
In Hui Jiang’s paper, the analysis of (refered to as the “disparity matrix”) is used to explore the loss landscape of general neural networks, assuming they are expressive enough. The canonical representation that is used is the Fourier representation of functions over the input space (which is also linear and nicely behaved). Assuming the family of neural networks -convers that Fourier space (a strong assumption), this suggests that during optimization it would be very hard to have the diparity matrix not be of full rank, and therefore we shouldn’t be surprised that optimizing with SGD finds the global minimum.
Another paper by Julius Berner et al, analyzes shallow ReLU networks in order to start showing the connection between the parameteric space and canonical space (referred to as “realization space”) for an actual neural network. The main result shows “inverse stability” of the shallow neural network under certain, mild conditions on the weights. Informally, inverse stability is the property such that for a given parameterization and it’s corresponding canonical representation , all canonical representations close to have a corresponding parametric representation close to . Such a property suggests that optimizing in the parameteric space should behave like optimization in the canonical space. Another interesting thing in this paper, is that there is explicit discussion of the fact that while the canonical loss surface is convex (as we saw throughout this blog), shallow ReLU networks aren’t expressive enough to fill the entire canonical space. This means that the optimization objective in the canonical space is a convex loss function with a non-convex feasible set. We’ll see another, more digestible example of this in the next blog post.
Footnotes
-
The restriction to the halfspace of is true when is infinitesimal, otherwise we can’t neglect the term. In such a situation, which is what we see in actual SGD, the learning rate also plays a role in determining the direction of the gradient step. Also, large learning rates could even cause the gradient to step out of the halfspace of the canonical gradient, leading to a gradient step negatively correlated to the canonical one. ↩
-
Note that a linear canonical space is relevant for any kernel function simply by looking at the reproducing Hilbert space of the kernel. This means that we can mostly be safe in saying that there is some canonical representation which is linear. This space may be infinite-dimensional, but let’s not worry about that too much for now… ↩